

.svg)



Wrangling different security tools and report formats was my least favorite part about working in AppSec. Prior to DefectDojo, I spent more than 60% of my time on tasks that weren’t security related for the sake of reporting and providing high quality results to our dev teams (removing duplicates and false positives).
Whether you’re a DefectDojo veteran or new to DefectDojo and DevSecOps, I wanted to share some best practices on how to model your data for reporting, maximizing smart features, and overall efficiency.
The DefectDojo data model is made to be flexible to fit complex organizations because it is difficult, costly, and primed for failure to ask an organization to rewrite their processes to conform to a tool’s opinionated way of looking at vulnerability management.
When setting up DefectDojo, you don’t have to have your structures perfect, as it is easy to move data around. You also do not have to take a “one structure fits all” approach.
Before diving in, here is what the DefectDojo data model looks like at a high level:
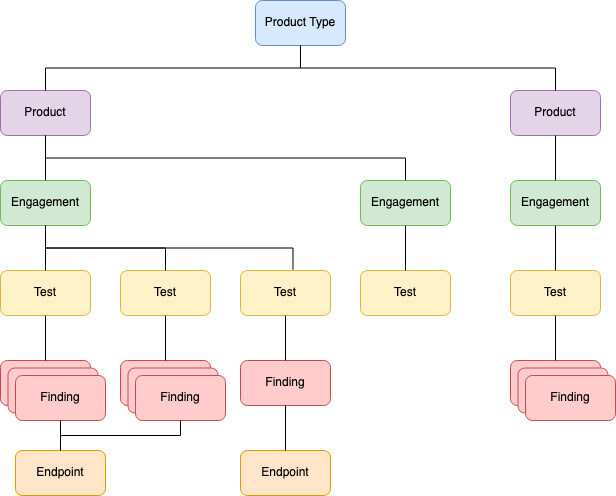
At the highest level of DefectDojo is the notion of a Product Type. Product Types can be business units, divisions, product families, etc. The important concept is that a Product Type is a container of Products that should be reported on as a group.
DefectDojo Products can be thought of as applications, individual repositories, projects, or even infrastructure regions. The three key concepts for DefectDojo Products, are:
- A Product should have a manager to ultimately own remediation or divvying up findings. (Findings can also have individual owners in the Pro Edition, but having a manager is important for both reporting and remediation.)
- Smart functions like deduplication, smart upload, false positive history, and reimport, are designed to work at a Product level, and thus you should consider “Do I want these findings to be compared against one another or should I store them in a different bucket (Product)?”
- If you’re using our JIRA integration, a DefectDojo Product must map to a single JIRA Project. The idea is clean project management and defined owners. However you can map multiple Dojo Products to a single JIRA project, if desired.
Attached to Products are Engagements. The two types of engagements are “CI/CD” Engagements and “Interactive Engagements”. Engagements are a bucket for different security scans run at a specific point in time. For CI/CD engagements, this bucket is great for ensuring that all your required tests have been completed in your CI/CD platform of choice (GitHub Actions, GitLab, Jenkins, Azure DevOps, etc). Interactive Engagements are to accommodate more traditional security testing performed by a human. While still a collection of the results from different security tools, Interactive Engagements are both a bucket for reporting, but also for proving the tests that were performed in the context of an audit or company requirements. I.E. prove to your PCI auditor that these types of tests were done with X results.
Attached to Engagements are Tests which are the individual security tools that ran against your Product. There is also a “Pen Test” Test Type if you would like to store manually recorded Findings with Findings from your Security Tools.
Findings have Endpoints which is where a Finding is located. For infrastructure heavy teams, this model can be flipped to look at Findings on a Per Endpoint Basis, rather than a Per Product Basis. Only “dynamic” findings have Endpoints. If a finding is “static” in nature we instead store the file name, line number, and repo at the Finding level.
My final pro tip is: To start leveraging DefectDojo immediately, you do not have to have all these pieces defined. You can opt to simply send scans to DefectDojo and DefectDojo will automatically create the structures it sees in your security tools. This can be done by using our API with the option “auto_create_context” set to True.
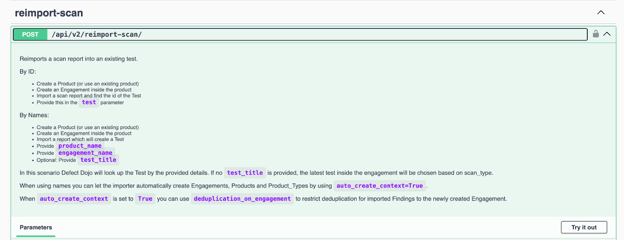
The key is flexibility, the ability to iterate, and above all else, drive immediate value. DefectDojo is designed to be flexible so you don’t have to worry about getting stuck. Start with our open source version we publish in partnership with OWASP, or go Pro for additional smart features, automatic upgrades, and support.
References: